R CSV 文件
R 作为统计学专业工具,如果只能人工的导入和导出数据将使其功能变得没有意义,所以 R 支持批量的从主流的表格存储格式文件(例如 CSV、Excel、XML 等)中获取数据。
CSV 表格交互
CSV(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号) 是一种非常流行的表格存储文件格式,这种格式适合储存中型或小型数据规模的数据。
由于大多数软件支持这个文件格式,所以常用于数据的储存与交互。
CSV 本质是文本,它的文件格式极度简单:数据一行一行的用文本保存起来而已,每条记录被分隔符分隔为字段,每条记录都有同样的字段序列。
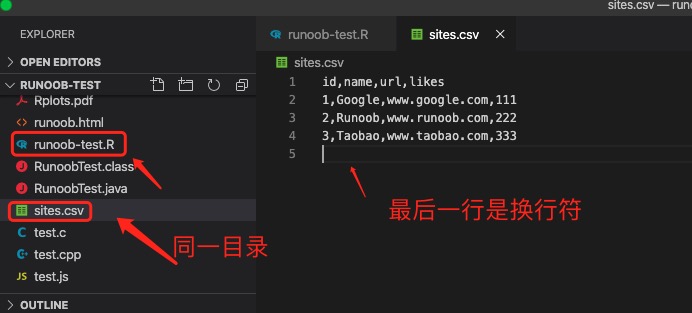
以下是一个简单的 sites.csv 文件(存储在测试程序的相同目录下):
id,name,url,likes1,Google,www.google.com,1112,Runoob,www.runoob.com,2223,Taobao,www.taobao.com,333
CSV 用逗号来分割列,如果数据中含有逗号,就要用双引号将整个数据块包括起来。
注意:包含非英文字符的文本要注意保存的编码,由于很多计算机普遍使用 UTF-8 编码,所以我是用 UTF-8 进行保存的。
注意: CSV 文件最后一行需要保留一个空行,不然执行程序会有警告信息。
Warning message:In read.table(file = file, header = header, sep = sep, quote = quote, : incomplete final line found by readTableHeader on 'sites.csv'
读取 CSV 文件
接下来我们就可以使用 read.csv() 函数来读取 CSV 文件的数据:
实例
print(data)
如果不设置 encoding 属性,read.csv 函数将默认以操作系统默认的文字编码进行读取,如果你使用的是 Windows 中文版系统且没有设置过系统的默认编码,那系统的默认编码应该是 GBK。所以大家请尽可能地统一文字编码以防出错。
执行以上代码输出结果为:
id name url likes1 1 Google www.google.com 1112 2 Runoob www.runoob.com 2223 3 Taobao www.taobao.com 333
read.csv() 函数返回的是数据框,我们可以很方便的对数据进行统计处理,以下实例我们查看行数和列数:
实例
print(is.data.frame(data)) # 查看是否是数据框
print(ncol(data)) # 列数
print(nrow(data)) # 行数
执行以上代码输出结果为:
[1] TRUE[1] 4[1] 3
以下统计数据框中 likes 字段最大对数据:
实例
# likes 最大的数据
like <- max(data$likes)
print(like)
执行以上代码输出结果为:
[1] 333
我们也可以指定查找条件,类似 SQL where 子句一样查询数据,需要用到到函数是 subset()。
以下实例查找 likes 为 222 到数据:
实例
# likes 为 222 的数据
retval <- subset(data, likes == 222)
print(retval)
执行以上代码输出结果为:
id name url likes2 2 Runoob www.runoob.com 222
注意:条件语句等于使用 ==。
多个条件使用 & 分隔符,以下实例查找 likes 大于 1 name 为 Runoob 的数据:
实例
# likes 大于 1 name 为 Runoob 的数据
retval <- subset(data, likes > 1 & name=="Runoob")
print(retval)
执行以上代码输出结果为:
id name url likes2 2 Runoob www.runoob.com 222
保存为 CSV 文件
R 语言可以使用 write.csv() 函数将数据保存为 CSV 文件。
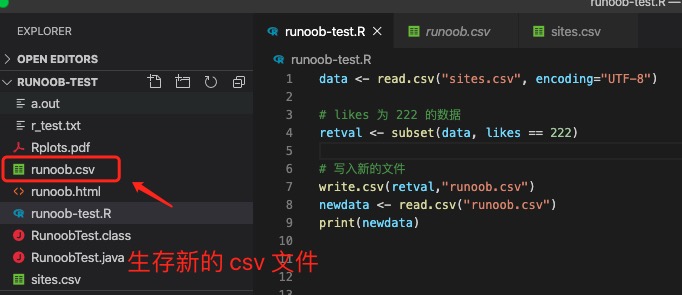
接着以上实例,我们将 likes 为 222 的数据 保存到 runoob.csv 文件:
实例
# likes 为 222 的数据
retval <- subset(data, likes == 222)
# 写入新的文件
write.csv(retval,"runoob.csv")
newdata <- read.csv("runoob.csv")
print(newdata)
执行以上代码输出结果为:
X id name url likes1 2 2 Runoob www.runoob.com 222
X 来自数据集 newper,可以通过参数 row.names = FALSE 来删除它:
实例
# likes 为 222 的数据
retval <- subset(data, likes == 222)
# 写入新的文件
write.csv(retval,"runoob.csv", row.names = FALSE)
newdata <- read.csv("runoob.csv")
print(newdata)
执行以上代码输出结果为:
id name url likes1 2 Runoob www.runoob.com 222
执行完后,我们就可以看到 runoob.csv 文件生存: